Introduction
As announced in the previous article, I am working on a new data project (aka The All Roads Project). This is going to be focused on analysis of the Catechism of the Catholic Church (CCC). The goal is to see the lineage of this book’s teachings to as many references as possible. This is an endeavor that will require some devotion.
This article will focus on the initial data collection. As there are many interconnected books, there needs to be a multi-versioned approach to the scope of the project. Initially, only the CCC and the Catholic Bible will be brought into the system. Once an initial version is complete, I will work on adding in more sources as time allows. This staged approach is necessary to avoid a situation where the project never gets to its initial version.
Data Sources
CCC
There are different websites containing the CCC. The versions on the Vatican1 and United States Conference of Catholic Bishops (USCCB)2 sites seem to be the best. Given that the Vatican site is organized as a basic set of URLs, I will use that version. However, I will also use the USCCB as a reference since it’s formatted in an easier-to-read style.
Abbreviations
The references used in the CCC are often abbreviated. This could cause an issue when pulling in new text for analysis. There will need to be a cross-reference containing the definition of these abbreviations. Fortunately, there are existing pages available such as those found on St. Charles Borromeo Catholic Church’s Website3.
Bible
The version of the Bible referred to by both the Vatican and USCCB is the New American Bible. The USCCB text is also referenced by the Vatican site, so I will utilize that version4.
Data Collection Process
To keep the approach simple and to the point, I am only interested in the text and related URLs for all sources. Fortunately, I already have a process that pulls URLs and related text. This has been previously discussed. Given that the Bible is a collection of books does increase complexity. This requires minor customization to the original logic. You can see those changes in the appendix section below. I am also using awk5 to cleanup of the shortened URLs. This step is executed for purposes of file organization.
Specific for the CCC, I am only collecting text related to the teachings under a single directory. Text and URL elements will only be collected from the individual pages. Embedded tags are not to be extracted. The final file name will be the extract identifier generated by the process along with the prefix “CCC” and “txt” extension.
The CCC Abbreviations List is a simple copy and paste from the source website into a spreadsheet. Once the source data are in the spreadsheet, I will clear out any unnecessary items and export to a csv file named “CCC.abbrevations.csv.”
Specific for the Bible, I will only pull the preface, introductions, and chapters. The text file for each chapter will be stored within a directory named to match the name of the book. For example, for the book “1 John,” there will be a directory named “1 John.” The individual chapters will be a text file containing the book name and number of the chapter as part of the file name. The extension is “txt.” This naming format will keep organization simple.
Data Metrics
With the data sources collected, here are some basic metrics from the various sources calculated using the wc command:
| Source | Number of Files | Number of Lines | Word Count | Bytes |
|---|---|---|---|---|
| CCC | 374 | 26153 | 275089 | 1556421 |
| Bible | 1394 | 304739 | 2037330 | 11833151 |
| CCC Abbrevations | 1 | 136 | 363 | 4123 |
Initial Review Notes
Reviewing the text, there are some items of note for the CCC:
- A header exists that contains common navigation text.
- A list of chapters the paragraphs are contained in also exists at top of file.
- The main body is composed of the paragraphs that are the teaching.
- Paragraphs might be preceded with a numeric identifier.
- Reference note identifiers may be located anywhere in the lines.
- Below main body are any references along with shared footer
The Bible is straightforward but there are also items of note:
- In the header, there is text relaying the common menu of items in the web site.
- Underneath the menu text are a list of navigation elements for the book.
- The body is typically composed of passages.
- A passage is typical preceded with a numeric identifier.
- Reference note identifiers may be located anywhere throughout the text.
- Below the main body are the reference listings.
- The footer contains further navigation text.
Further evaluation of the structure will be discussed in the data preparation stage. It is important to note that there is a structure to the texts.
Next Steps
With the data now collected, we are ready to move onto the important discussion of the database engine. There are many choices but will probably come down to whether to use a RDBMS or a NoSQL variety. That help will direct the path to take with the data preparation and load.
Thank you
Appendix
Shortcuts
This Shortcut is used to extract the highest level of the Bible URLs.
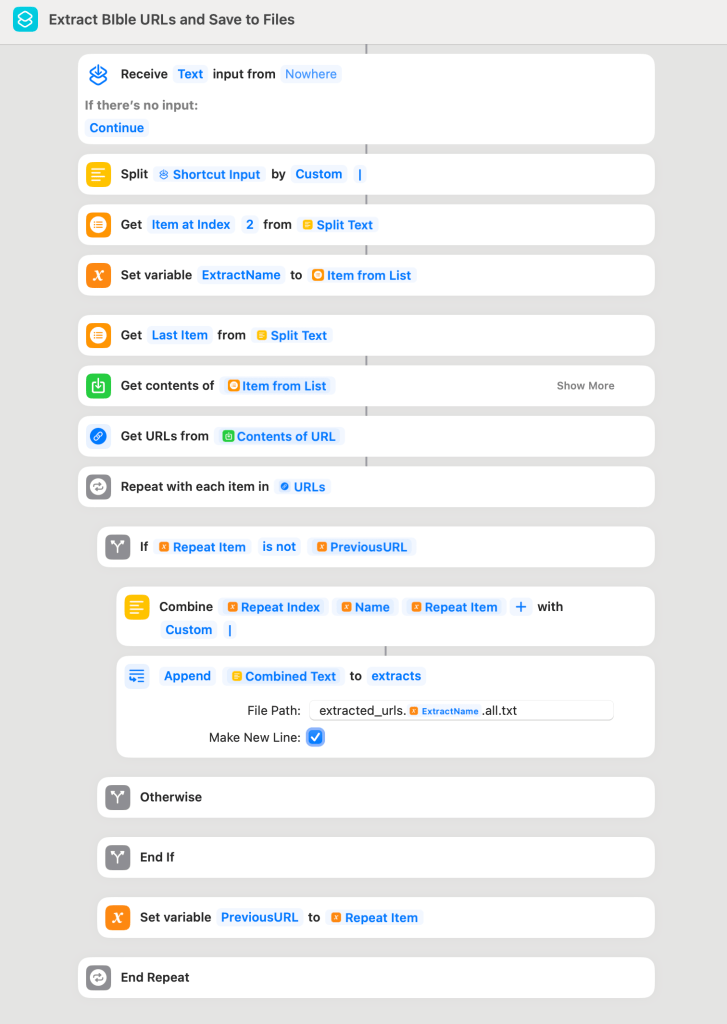
This Shortcut is used to pull the individual pages using the files from the previous step and cleaned with awk script.

awk Scripts
This awk script extracts and formats the URLs needed for the Bible.
# Date: 14-APR-2024
# Author: Andy Della Vecchia
# Purpose: Parse out relevant url sections for Bible Chapters
BEGIN {
# these are used to track where the read is in the file
end_flag = 0
# get the file name being processed
split(ARGV[1], file_pieces, ".all.txt")
split(file_pieces[1], file_pieces, "extracted_urls.")
fn = file_pieces[3s]
print "ARGV[1]: " ARGV[1]
print "PWD: " ENVIRON["PWD"]
print "fn: " fn
# build out the paragraph and reference parts
out_path = "\.\.\/extracted_urls_files\/Bible_urls_clean\/"
file_out = out_path "extracted_urls." fn ".clean.txt"
print "file_out: " file_out
}
{
# Check to see if the end of needed URLs is reached (when "|Privacy Policy|" or reference "#" is read)
end_flag = ($0 ~ /\|Privacy Policy\|/) || ($0 ~ /\#/) || end_flag
# print only when the end has not been meet and not in the header list of URLs
if (!end_flag && NR > 52) {
if ($0 ~ /\53|Next chapter Next chapter\|/) {
split($0, parsed_line, "/")
chapter_number = parsed_line[NF]
gsub(/\|Next chapter Next chapter\|/, "\|" chapter_number "\|")
}
gsub(/\|\/bible\//,"|https://bible.usccb.org/bible/")
print $0 >> file_out
}
}References
[1] Vatican. Catechism of the Catholic Church. Retrieved from: https://www.vatican.va/archive/ENG0015/_INDEX.HTM
[2] United States Conference of Catholic Bishops. Catechism of the Catholic Church. Retrieved from: https://www.usccb.org/beliefs-and-teachings/what-we-believe/catechism/catechism-of-the-catholic-church
[3] St. Charles Borromeo Catholic Church. Catechism of the Catholic Church – Abbreviations. Retrieved from: http://www.scborromeo.org/ccc/abbrev.htm
[4] United States Conference of Catholic Bishops. Books of the Bible. Retrieved from: https://bible.usccb.org/bible
[5] Geeks for Geeks. AWK command in Unix/Linux with examples. Retrieved from: https://www.geeksforgeeks.org/awk-command-unixlinux-examples/

2 responses to “The All Roads Project – Collecting Heavenly Data”
[…] start by getting a better grasp of the data. In the previous step, the texts for the Catechism of the Catholic Church (CCC) and Bible were extracted. I did make some […]
LikeLike
[…] until now, the work for The All Roads Project has been more high level. The final table structures are defined in the previous article. That step does gets more detailed […]
LikeLike